
Table de Matieres
I. Présentation
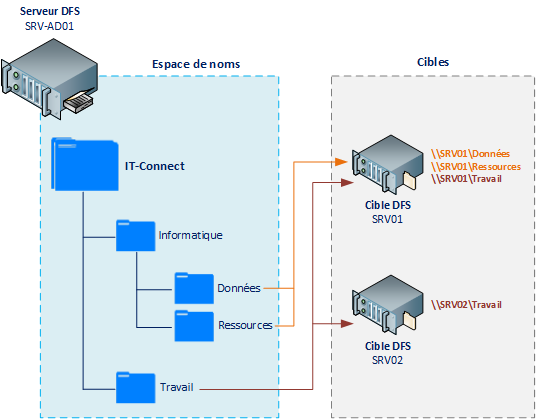
Dans ce tutoriel, faisant suite aux précédents sur le DFS et DFSR, nous allons mettre en application le DFS et le DFSR, le premier permet aux utilisateurs l’accès aux données distribuées, le second assurera la réplication entre les cibles.
II. Les éléments du groupe
Si l’on reprend l’architecture suivie depuis le début, on peut voir qu’une réplication des données est nécessaire entre « \\SRV01\Travail » et « \\SRV02\Travail » puisqu’ils sont tous les deux cibles de la liaison DFS « Travail ». Les données contenues sur ces deux serveurs concernant la liaison DFS « Travail » doivent être identiques, donc synchronisées.
III. Le filtrage des fichiers
Il est à noter que la configuration par défaut du DFSR, applique certaines règles de filtrage concernant la synchronisation des fichiers.
Plusieurs filtres s’appliquent afin d’exclure des fichiers :
– Fichier avec l’extension « .tmp »
– Fichier avec l’extension « .bak »
– Fichier dont le nom commence par le signe « ~ »
– Points de montage NTFS
– Fichier chiffré par EFS (Encrypting File System)
Libre à vous d’exclure certains fichiers ou dossiers, notamment les fichiers vidéos par exemple pour éviter de consommer trop de bande passante, ou encore, une base de données car c’est généralement de la donnée sensible et pas toujours évidente à manipuler.
IV. Configuration du groupe de réplication
Commencez par ouvrir la console « Gestion du système de fichiers distribués DFS », ensuite faites un clic droit sur le module « Réplication » et cliquez sur « Nouveau groupe de réplication ».
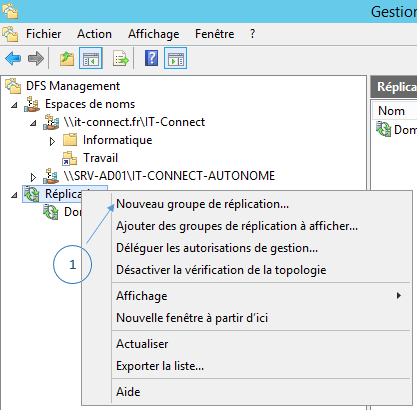
Un assistant s’exécute…
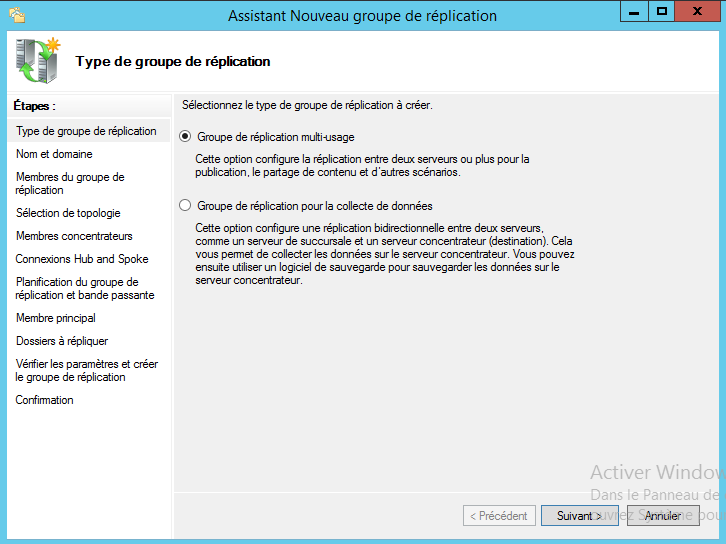
Sélectionnez le type de groupe de réplication. Dans notre cas, on sélectionne « Groupe de réplication multi-usage » car il s’agit de la réplication entre deux serveurs. Si vous utilisez un groupe de réplication pour concentrer les données de plusieurs serveurs sur un seul et même serveur central, il est préférable d’opter pour « Groupe de réplication pour la collecte de données ».
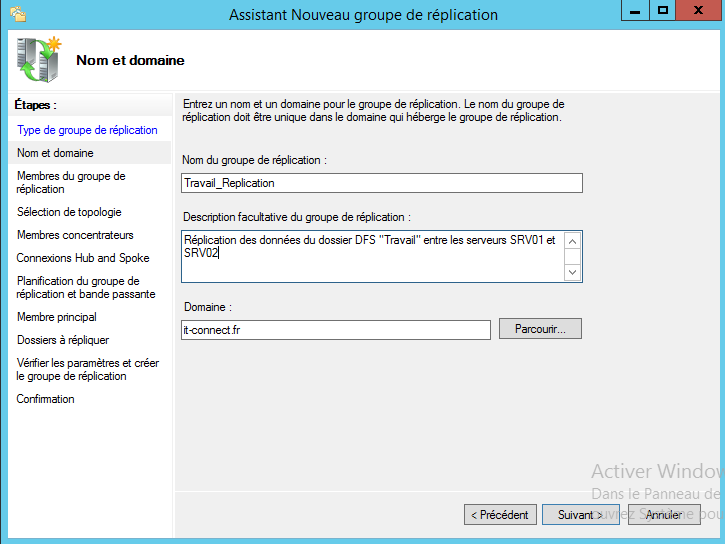
Nommez le groupe de réplication, saisissez éventuellement une description, puis, continuez en cliquant sur « Suivant ».
Indiquez les serveurs membres en cliquant sur « Ajouter ». Pour ma part, il s’agit de SRV01 et SRV02. Cliquez sur « Suivant » une fois les membres ajoutés.
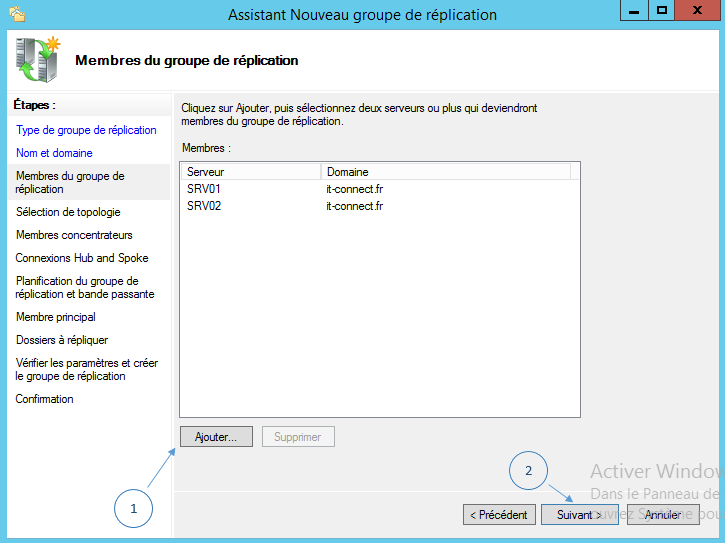
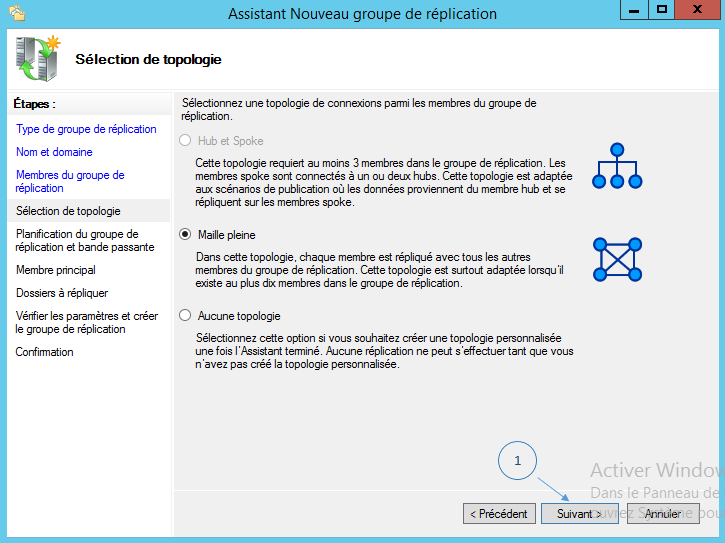
Sélectionnez le mode de topologie qui vous convient, pour cela il suffit de lire la description de chaque mode. Le mode « Maille pleine » suffira pour la majorité des cas lorsqu’il n’y a pas plus de 10 serveurs.
Cliquez sur « Suivant » une fois votre choix effectué.
Cette étape concerne l’allocation de la bande passante et les horaires pendant laquelle la réplication est autorisée. Si vous sélectionnez « Répliquer en continu à l’aide de la bande passante spécifiée », la réplication sera effectuée en temps réel en se limitant à l’utilisation de la bande passante indiquée.
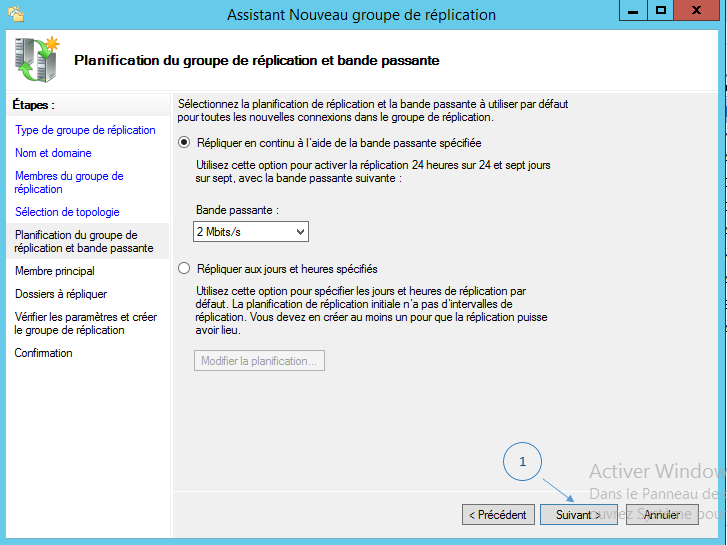
Si vous choisissez « Répliquer aux jours et heures spécifiés », cliquez sur « Modifier la planification » pour définir des périodes d’activités pour la réplication. Voici ce que l’on pourrait imaginer :
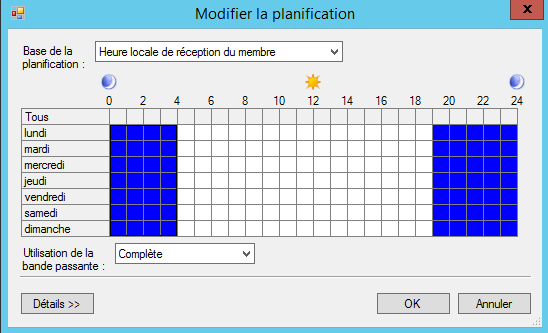
Ceci permettrait de répliquer les données la nuit en utilisant la bande passante complète.
Sélectionnez le serveur principal, c’est-à-dire le serveur contenant les données initiales. Le meilleur cas de figure étant celui où les serveurs membres commencent tous les deux avec des dossiers vides.
Étant donné que les données situées sur le serveur sélectionné feront autorité sur les données stockées sur les autres membres, notamment en cas de conflits.
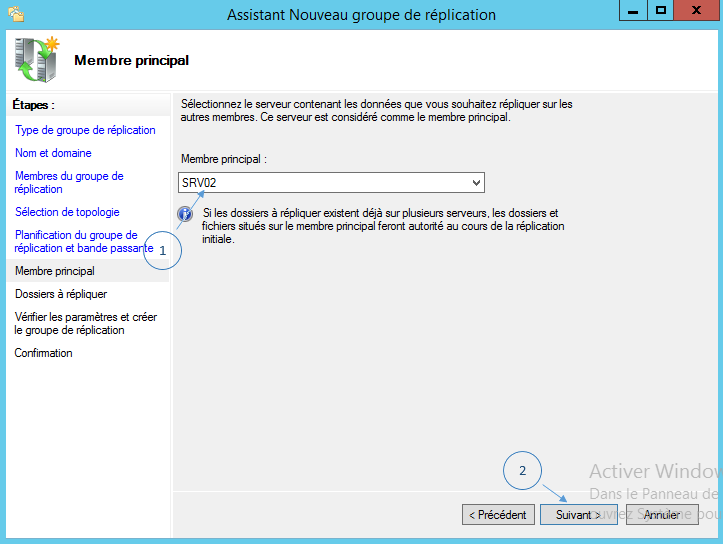
Cliquez sur « Suivant » lorsque le choix est pris.
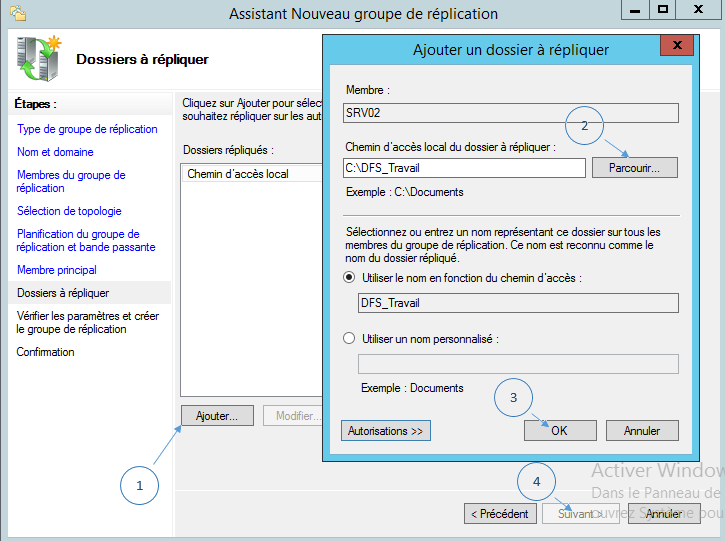
Vous devez indiquer le chemin vers le dossier à répliquer, ce dossier étant forcément sur le serveur membre principal précisé à l’étape précédente. Pour ma part le répertoire « C:\DFS_Travail » correspond au partagé réseau « Travail », cible de la liaison DFS « Travail ». Cliquez éventuellement sur « Autorisations » pour modifier les droits, sinon les autorisations existantes seront appliquées.
Ensuite, validez en appuyant sur « OK » puis sur « Suivant ».
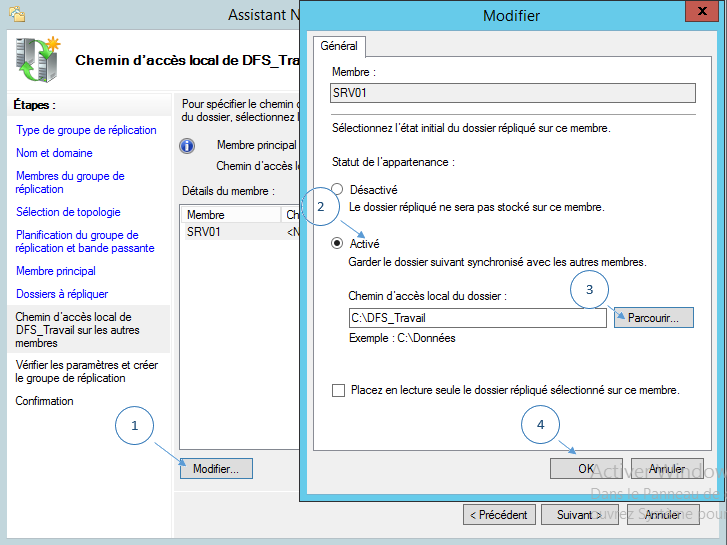
Désormais, pour chaque membre du groupe de réplication, vous devez indiquer si le dossier local du serveur principal doit être répliqué ou non. S’il doit être répliqué, vous devez indiquer quel dossier de destination doit être utilisé pour stocker les données répliquées.
Je sélectionne le serveur « SRV01 » qui est le second serveur du groupe. Ensuite un clic sur « Modifier » permettra d’afficher les paramètres. Il suffit de cocher la case « Activé » et d’indiquer le chemin vers le dossier local. Cliquez sur « OK » pour valider et « Suivant » pour continuer.
Il est à noter que vous pouvez définir ce répliqua de données en lecture seule uniquement en cochant l’option adéquat.
Il est important de préciser en tant que répertoire de destination le répertoire indiqué en tant que cible au niveau de la liaison DFS, ceci dans le but que les données soient accessibles du côté des utilisateurs. Il ne s’agit pas de faire une réplication en tant que « sauvegarde » dans ce cas.
Cliquez sur « Créer » pour que le groupe de réplication soit créé. Patientez et cliquez sur « Fermer ». Vous devez attendre avant que la réplication se déclenche le temps que la configuration soit déployée.
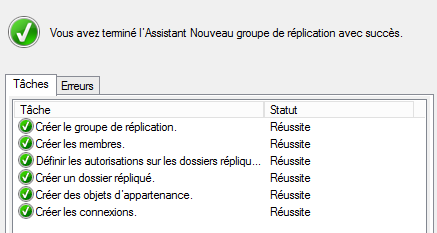
La création du groupe de réplication est désormais terminée, et ce dernier est opérationnel.
Hébergez votre site à partir de 2$ sur 👉👉👉![]()

