

Table de Matieres
I. Présentation
Dans ce tutoriel, nous allons apprendre à installer et configurer la déduplication sous Windows Server 2022, même si cette procédure s’applique aussi aux versions précédentes : Windows Server 2019 et Windows Server 2016. Avant d’étudier la déduplication dans la pratique, il me semble important de vous proposer une introduction théorique au principe de la déduplication.
II. Le principe de la déduplication
La déduplication de données, ou Dedup pour les intimes, est une fonctionnalité très pratique sur les espaces de stockage dont l’objectif principal est d’optimiser l’espace disque. Grâce à ce mécanisme qui vise à rechercher les parties dupliquées entre les fichiers, l’espace disque utilisé par les données est réduit considérablement. En fonction des usages, le gain en espace disque peut aller de 30% à 95% !
Si l’on regarde les propriétés d’un dossier présent sur un volume où il n’y a pas de déduplication de données, on peut voir que la « Taille » et la « Taille sur le disque » sont identiques, car il n’y a pas d’optimisation. Après avoir mis en place la déduplication de données, le résultat sera totalement différent comme nous le verrons par la suite.
 100vw, 469px » data-lazy-src= »https://tuto.cm/wp-content/uploads/2024/09/1726005881_734_Installer-et-configurer-la-deduplication-sous-Windows-Server-2022.png » /><noscript><img loading=)
Pour optimiser l’espace de stockage, le service de déduplication va découper chaque fichier en blocs, associer un identifiant unique à chaque bloc et stocker ces informations dans un index, dans le but d‘identifier les blocs communs entre l’ensemble des fichiers. Ainsi, le serveur va stocker qu’une seule copie de chaque bloc et utiliser un système de pointeurs pour que chaque fichier puisse être reconstitué normalement. En utilisant cette méthode, on économise de l’espace disque !
 100vw, 597px » data-lazy-src= »https://tuto.cm/wp-content/uploads/2024/09/1726005881_399_Installer-et-configurer-la-deduplication-sous-Windows-Server-2022.png » /><noscript><img loading=)
Depuis plusieurs années, le principe de la déduplication de données est utilisé par les logiciels de sauvegarde, notamment Veeam et Altaro, car il permet d’économiser énormément d’espace disque sur l’espace de stockage dédié aux sauvegardes.
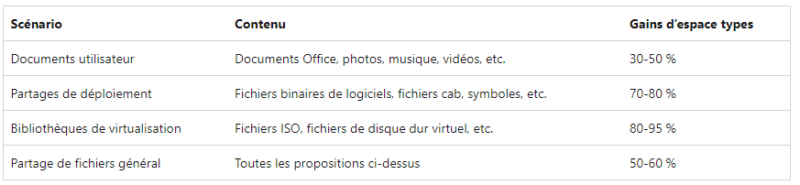
En environnement Microsoft, il y a plusieurs cas d’usage où il est intéressant d’utiliser la déduplication de données pour avoir un gain de place important. Ci-dessous, la liste des scénarios prit en charge par Windows Server, avec une configuration adaptée :
- Serveurs de fichiers où les utilisateurs stockent leurs données, mais également où il y a de la redirection de dossiers
- Environnement VDI (virtualisation de postes de travail)
- Applications de sauvegarde virtualisées
III. Installer la déduplication sur Windows Server 2022
Pour installer la fonctionnalité « Déduplication des données » de Windows Server, il est possible d’utiliser le Gestionnaire de serveur, Windows Admin Center ou PowerShell. Voici la commande PowerShell à utiliser :
Install-WindowsFeature -Name FS-Data-Deduplication
À partir du Gestionnaire de serveur, voici le rôle à sélectionner sous « Services de fichiers et de stockage » :
 100vw, 784px » data-lazy-src= »https://tuto.cm/wp-content/uploads/2024/09/1726005882_458_Installer-et-configurer-la-deduplication-sous-Windows-Server-2022.png » /><noscript><img loading=)
L’installation est relativement rapide…
 100vw, 783px » data-lazy-src= »https://tuto.cm/wp-content/uploads/2024/09/1726005882_158_Installer-et-configurer-la-deduplication-sous-Windows-Server-2022.png » /><noscript><img loading=)
IV. Configurer la déduplication sur Windows Server
Ce rôle n’a pas sa propre console MMC pour la configuration puisque c’est directement intégré au Gestionnaire de serveur dans la section « Services de fichiers et de stockage« . Ici, il faut cliquer sur « Disques » à gauche (2), sélectionner le disque qui contient le volume sur lequel on souhaite activer la déduplication (2), puis sélectionner le volume en question (3) et faire un clic droit dessus afin d’activer à l’option « Configurer la déduplication des données« .
Remarque : sur Windows Server, la déduplication s’active de façon indépendante pour chaque volume, sur chacun des disques du serveur. Dans cet exemple, c’est sur un disque dédié aux données, associé à la lettre « P » que la déduplication va être activée.
 100vw, 800px » data-lazy-src= »https://tuto.cm/wp-content/uploads/2024/09/1726005882_266_Installer-et-configurer-la-deduplication-sous-Windows-Server-2022.png » /><noscript><img loading=)
La première étape consiste à sélectionner un scénario d’usage. Ici, il s’agit d’un partage de fichiers classique donc je sélectionne « Serveur de fichiers à usage général« . Il y a également la possibilité de configurer d’autres options :
- Dédupliquer les fichiers de plus de (en jours) : 3 jours par défaut pour ce scénario, ce qui représente le délai entre l’écriture de la donnée et l’optimisation
- Extensions de fichier personnalisées à exclure : exclure certaines extensions de fichiers, en plus des extensions « edb » et « jrs«
- Exclure certains dossiers (et leur contenu) du processus de déduplication en cliquant sur le bouton « Ajouter«
Sous Windows Server, il faut garder à l’esprit que l’optimisation n’est pas effectuée en temps réel : les données sont écrites sur le disque (sans optimisation), puis il y a un traitement qui effectue l’optimisation des données.
 100vw, 642px » data-lazy-src= »https://tuto.cm/wp-content/uploads/2024/09/1726005883_125_Installer-et-configurer-la-deduplication-sous-Windows-Server-2022.png » /><noscript><img loading=)
En cliquant sur le bouton « Définir la planification de la déduplication« , on peut accéder à d’autres options. L’option « Activer l’optimisation en arrière-plan » est cochée par défaut : par la suite, si vous constatez que la déduplication consomme trop de ressources (CPU) sur le système, vous pouvez essayer de désactiver cette option.
Il y a également la possibilité de planifier l’optimisation du stockage, selon certains jours de la semaine, en configurant les options « Activer l’optimisation du débit » et « Créer une deuxième planification d’optimisation du débit« . Ce n’est pas nécessaire si l’optimisation en arrière-plan est activée.
 100vw, 624px » data-lazy-src= »https://tuto.cm/wp-content/uploads/2024/09/1726005883_169_Installer-et-configurer-la-deduplication-sous-Windows-Server-2022.png » /><noscript><img loading=)
Validez par deux fois afin de confirmer la configuration et l’activation de la déduplication sur ce volume. Le statut de la déduplication s’affiche dans le Gestionnaire de serveur via les colonnes « Taux de déduplication » et « Gain de déduplication« .
 100vw, 800px » data-lazy-src= »https://tuto.cm/wp-content/uploads/2024/09/1726005884_494_Installer-et-configurer-la-deduplication-sous-Windows-Server-2022.png » /><noscript><img loading=)
Au-delà du processus d’optimisation, le service de déduplication est lié à trois tâches planifiées que l’on peut lister avec la commande PowerShell suivante :
Get-DedupSchedule
Et que l’on peut également visualiser via le « Planificateur de tâches » de la machine, à l’endroit suivant : Microsoft > Windows > Deduplication.
 100vw, 800px » data-lazy-src= »https://tuto.cm/wp-content/uploads/2024/09/1726005884_530_Installer-et-configurer-la-deduplication-sous-Windows-Server-2022.png » /><noscript><img loading=)
Maintenant, il ne reste plus qu’à patienter que Windows Server effectue son travail…. Mais si vous souhaitez déclencher l’optimisation maintenant, ce qui peut être intéressant pour faire de simples tests, vous pouvez exécuter la tâche « BackgroundOptimisation« . Tout en sachant que cette tâche s’exécute toutes les heures !
À partir de PowerShell, on peut également lancer la tâche d’optimisation (ou une autre tâche). Voici un exemple pour lancer la tâche sur le volume « P: » :
Start-DedupJob -Type Optimization -Volume P:
 100vw, 800px » data-lazy-src= »https://tuto.cm/wp-content/uploads/2024/09/1726005884_121_Installer-et-configurer-la-deduplication-sous-Windows-Server-2022.png » /><noscript><img loading=)
Ensuite, vous pouvez suivre l’avancement de la tâche avec cette commande :
Get-DedupJob
Suite à l’exécution de cette tâche, mon espace de stockage est optimisé ! On peut voir que le taux de déduplication est passé de 0% à 71% !
 100vw, 800px » data-lazy-src= »https://tuto.cm/wp-content/uploads/2024/09/1726005885_796_Installer-et-configurer-la-deduplication-sous-Windows-Server-2022.png » /><noscript><img loading=)
Avec la commande PowerShell ci-dessous, on peut obtenir des informations sur les résultats de l’optimisation (comme ci-dessous) :
Get-DedupStatus
 100vw, 800px » data-lazy-src= »https://tuto.cm/wp-content/uploads/2024/09/1726005885_854_Installer-et-configurer-la-deduplication-sous-Windows-Server-2022.png » /><noscript><img loading=)
Dans les propriétés du dossier, qui contient plusieurs fois le même package MSI, il y a également du changement puisque la taille sur le disque est passée à « 0 octet« . Ce résultat est tout de même un peu étonnant, car le serveur doit tout de même stocker une copie de mon fichier !
 100vw, 469px » data-lazy-src= »https://tuto.cm/wp-content/uploads/2024/09/1726005885_897_Installer-et-configurer-la-deduplication-sous-Windows-Server-2022.png » /><noscript><img loading=)
V. Conclusion
Grâce à ce tutoriel, vous êtes en mesure d’installer et de configurer la déduplication de données sur un serveur Windows Server ! En complément de cet article, vous pouvez prendre connaissance de la documentation officielle à ce sujet :
Hébergez votre site à partir de 2$ sur 👉👉👉![]()





